SynaptopathyDB
A scientific database and web platform that connects synaptic proteins, genes, mutations, diseases, and publications for synaptopathy research. Built as the main software surface for a project that became a Scientific Reports publication, with unified search, data exploration, export, and API access.
Researchers needed a way to query proteomic, genetic, and phenotypic data together instead of moving across disconnected papers, databases, and spreadsheet-like resources.
Built the full web platform: frontend architecture, backend API, search and autocomplete flows, data views, exports, and deployment.
The platform became part of a Scientific Reports paper where I am a co-first author and now serves as a public research resource.
Lead Web Developer
6 months
Reader-first case study
This case study focuses on problem framing, implementation choices, technical constraints, and outcome.
Lead Web Developer
6 months
Research project
2025
Where parts of the system are internal or institutional, this case study focuses on engineering scope, workflow design, and technical decisions rather than trying to simulate missing public artifacts.
Integrates data from 64 mammalian synapse proteomic studies into one searchable system
Surfaces 3,437 consensus synapse proteins linked to 1,266 OMIM diseases
Supports unified gene, disease, mutation, and publication exploration with export and API access
Overview
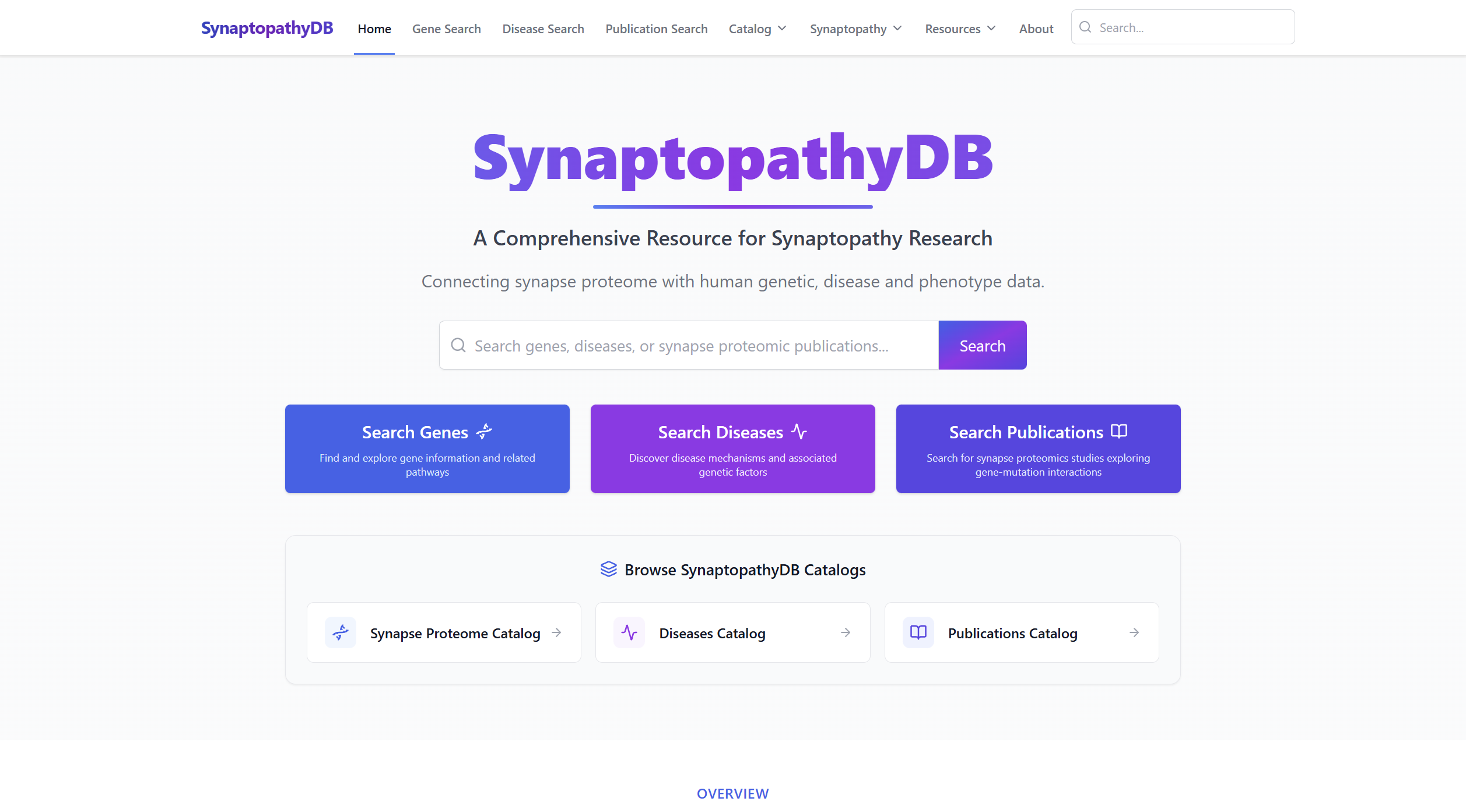
SynaptopathyDB is an online resource for studying the genetic and clinical basis of synaptopathies: disorders linked to mutations in genes encoding synaptic proteins. The platform brings together proteomic studies, disease associations, mutation data, and publication records so researchers can work from a single interface instead of stitching together evidence manually.
The project is one of the clearest public examples of the work I do at the University of Edinburgh: turning complex scientific data into a usable product with real research value.
Problem
The underlying science is rich, but the information landscape is fragmented. Researchers often need to move between proteomic studies, disease records, mutation databases, and publications just to answer basic questions such as:
- Which synaptic genes are associated with a disease?
- Which mutations have been reported for a gene?
- Which studies support a particular synaptic localisation?
- How do publication, disease, and protein records connect?
The challenge was not just to store the data. It was to design a system that let researchers navigate across these relationships quickly and with enough context to support real scientific work.
What I Built
I built the full web application, including the user-facing search experience, the backend API, and the application architecture around the data model provided by the research collaboration.
Core parts of the build included:
- Gene, disease, and publication views that connect records across the dataset instead of presenting them in isolation
- Autocomplete and identifier-aware search supporting multiple biological identifier systems and aliases
- Lazy-loaded tabs and progressive fetching so detailed pages stayed usable without front-loading every related record
- Export and API access so the platform could work both as a website and as a reusable data surface for downstream analysis
- Interactive visualisation endpoints for charts and summary views that help researchers inspect trends in the data
Technical Decisions
Frontend
The frontend was built as a modular React application with reusable search logic and domain-specific components. The priority was not visual flourish. It was helping researchers move quickly between records, filters, and related data without losing context.
Key frontend decisions included:
- Debounced autocomplete and identifier-aware search
- URL-driven state for shareable searches
- Lazy-loading detail panels to keep first-load performance reasonable
- Separate reusable components for search, pagination, export, and no-results flows
Backend
The backend was a Flask API on top of a substantial SQLite dataset, using SQLAlchemy and modular routes to expose search, detail, autocomplete, and statistics endpoints.
Important backend decisions included:
- Complex relational queries across genes, diseases, papers, and mutations
- Connection management tuned for longer-running scientific queries
- Programmatic access through API endpoints rather than a UI-only design
- Integration with external lookup services for protein-to-gene resolution
Constraints
This was not a generic content site. The platform had to handle:
- A large scientific dataset with multiple entity types and relationship paths
- Multiple biological identifier systems across species
- Research users who need both fast lookup and deep linked context
- A public-facing product surface that still needed to be trustworthy and maintainable
Outcome
SynaptopathyDB became part of a peer-reviewed publication in Scientific Reports, where I am a co-first author. More importantly, it turned a large, multi-source scientific dataset into something researchers could actually interrogate, browse, and reuse.
It is one of the strongest examples in this portfolio because it combines product thinking, data modelling, full-stack engineering, and research impact in one public system.
Links
- Live site: synaptopathydb.org
- Paper: Scientific Reports DOI